Seurat Curated Workflow
Irzam Sarfraz
Source:vignettes/articles/ui_seurat_curated_workflow.Rmd
ui_seurat_curated_workflow.RmdIntroduction
Seurat is an R package (Butler et al., Nature Biotechnology 2018 & Stuart, Butler, et al., Cell 2019) that offers various functions to perform analysis of scRNA-Seq data on the R console. In the singleCellTK, we implement all the common steps of the proposed workflow in an interactive and easy to use graphical interface including interactive visualizations. The purpose of this curated workflow is to allow the users to follow a standardized step-by-step workflow for an effortless analysis of their data.
General Workflow
A general workflow for the Seurat tab is summarized in the figure below: 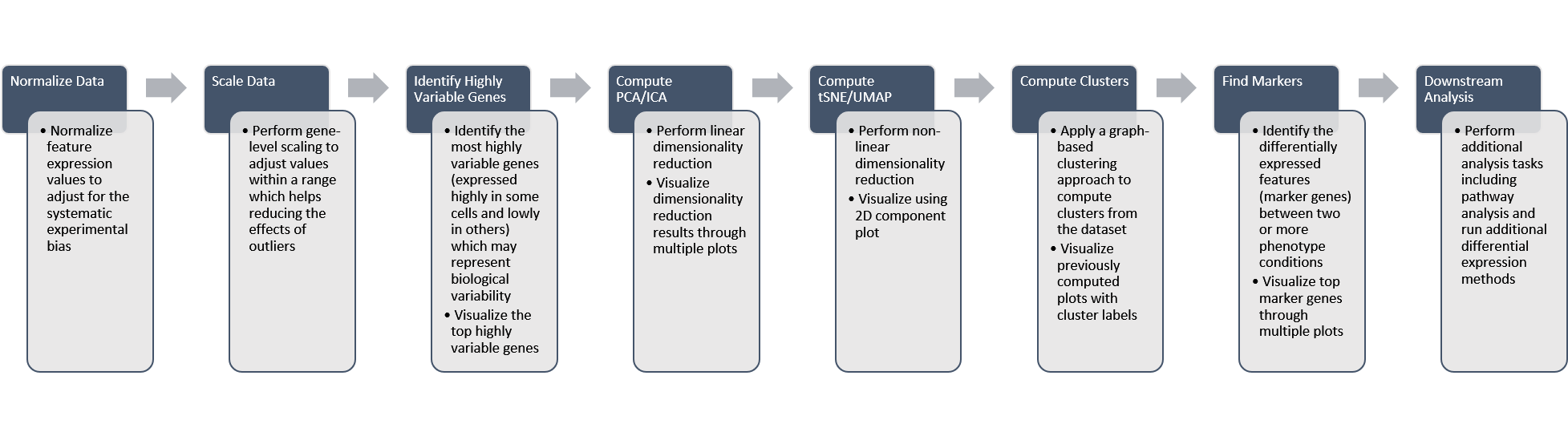
In this tutorial example, we illustrate all the steps of the curated workflow and focus on the options available to manipulate and customize the steps of the workflow as per user requirements. To initiate the Seurat workflow, click on the ‘Curated Workflows’ from the top menu and select Seurat.
NOTE: This tutorial assumes that the data has already been uploaded via the upload tab of the toolkit and filtered before using the workflow.
1. Normalize Data
Assuming that the data has been uploaded via the Upload tab of the toolkit, the first step for the analysis of the data is the Normalization of data. For this purpose, any assay available in the uploaded data can be used against one of the three methods of normalization available through Seurat i.e. LogNormalize, CLR (Centered Log Ratio) or RC (Relative Counts).
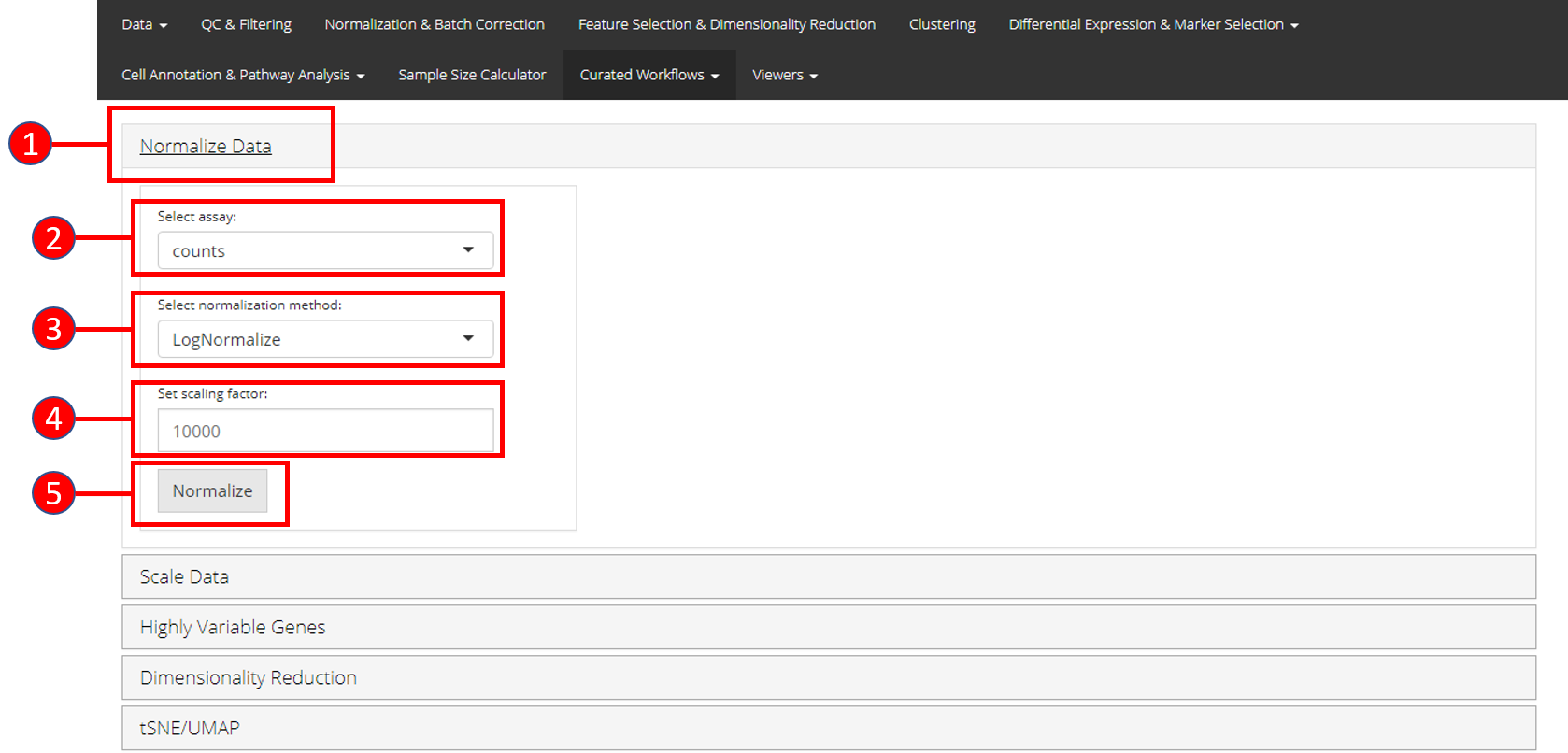
- Open up the ‘Normalize’ tab by clicking on it.
- Select the
assayto normalize from the dropdown menu. - Select the normalization method from the dropdown menu. Available methods are
LogNormalize,CLRorRC. - Set the scaling factor which represents the numeric value by which the data values are multiplied before log transformation. Default is set to
10000. - Press the ‘Normalize’ button to start the normalization process.
2. Scale Data
Once normalization is complete, data needs to be scaled and centered accordingly. Seurat uses linear (linear model), poisson (generalized linear model) or negbinom (generalized linear model) as a regression model.
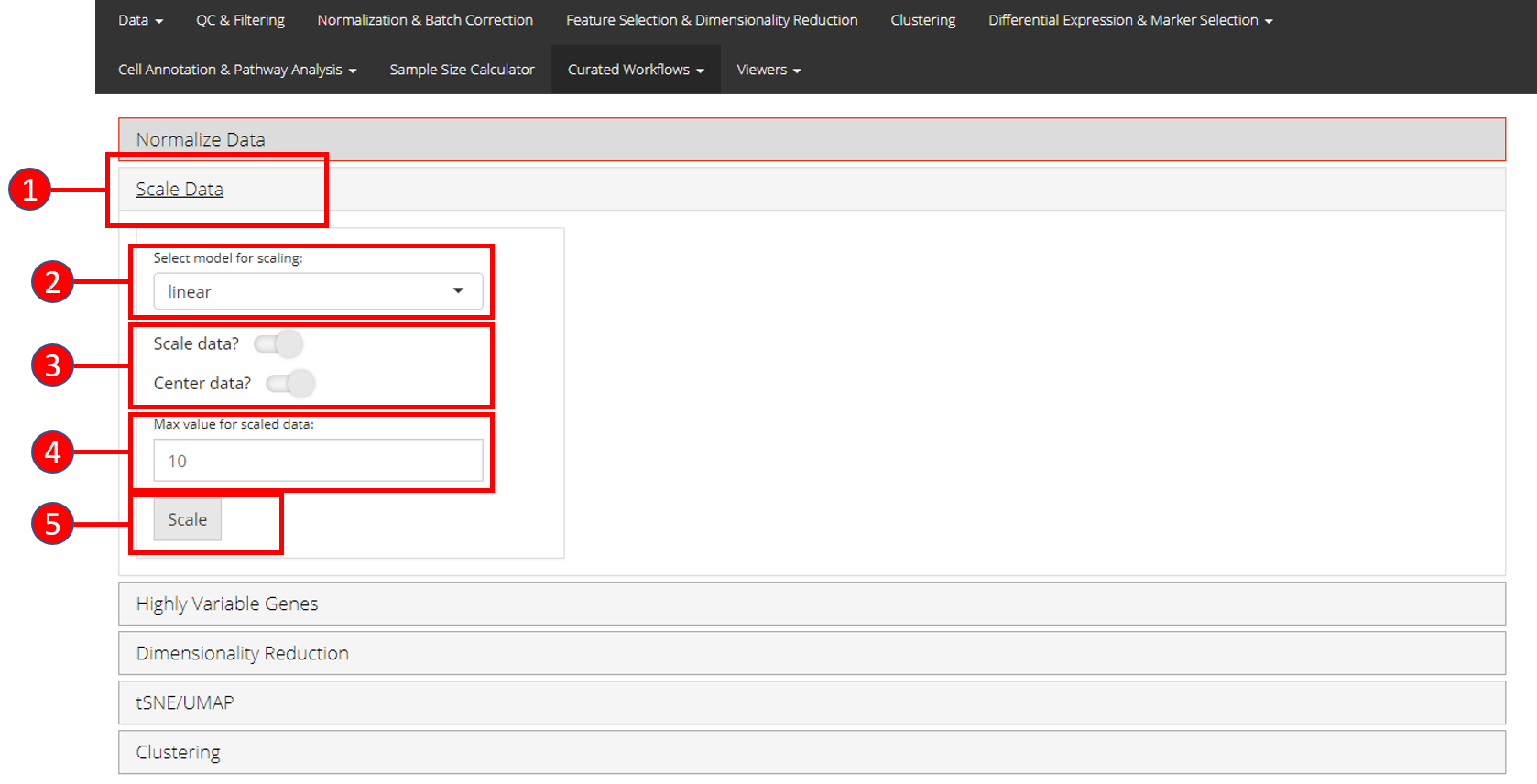
- Open up the ‘Scale Data’ tab.
- Select model for scaling from
linear,poissonornegbinom. - Select if you only want to scale data or center it as well.
- Input maximum scaled data value. This is the maximum value to which the data will be scaled to.
- Press ‘Scale’ button to start processing.
3. Highly Variable Genes
Identification of the highly variable genes is core to the Seurat workflow and these highly variable genes are used throughout the remaining workflow. Seurat provides three methods for variable genes identification i.e. vst (uses local polynomial regression to fit a relationship between log of variance and log of mean), mean.var.plot (uses mean and dispersion to divide features into bins) and dispersion (uses highest dispersion values only).
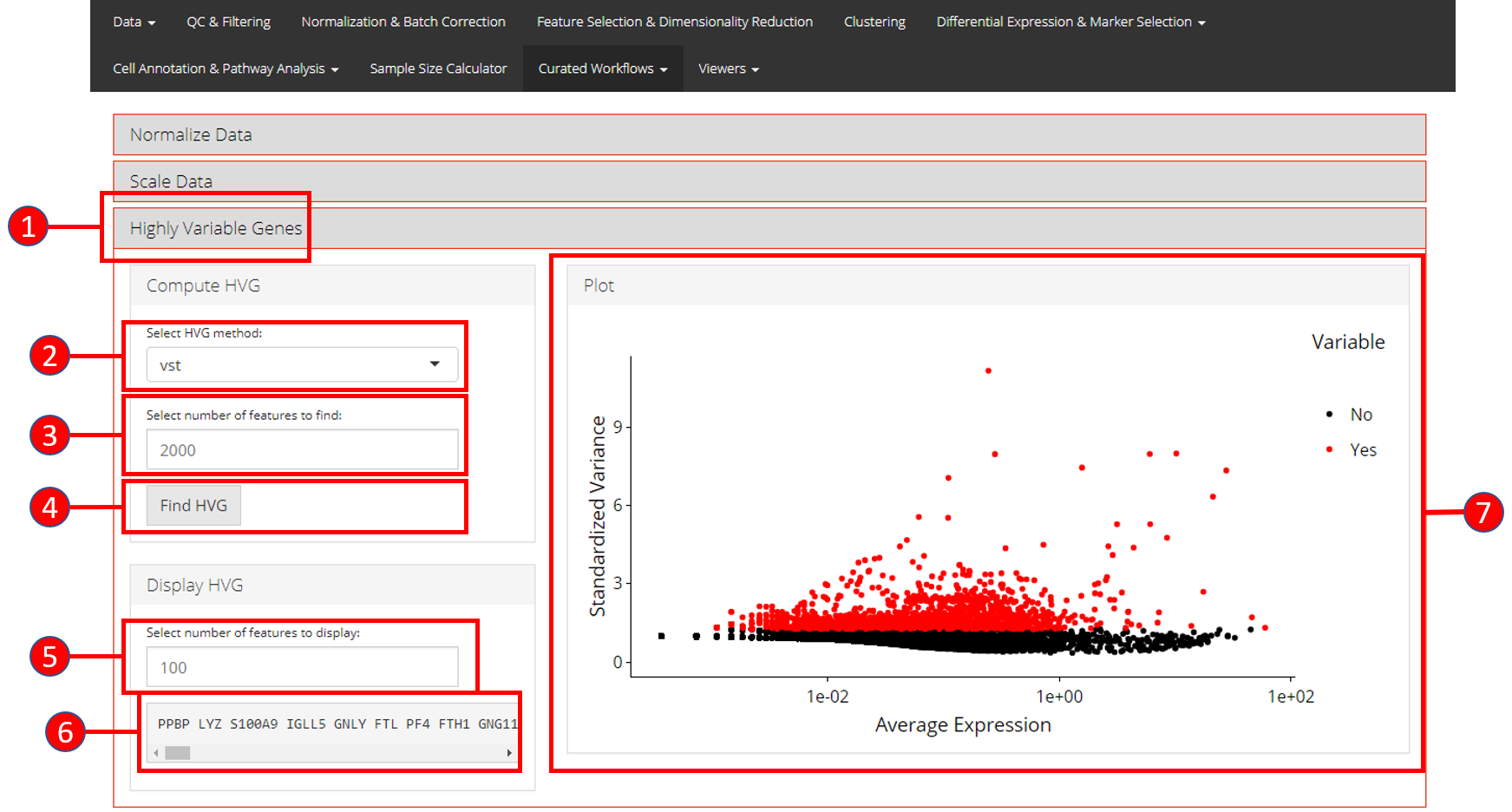
- Open up the ‘Highly Variable Genes’ tab.
- Select method for computation of highly variable genes from
vst,mean.var.plotanddispersion. - Input the number of genes that should be identified as variable. Default is
2000. - Press ‘Find HVG’ button to compute the variable genes.
- Once genes are computed, select number of the top most variable genes to display in (6).
- Displays the top most highly variable genes as selected in (5).
- Graph that plots each gene and its relationship based upon the selected model in (2), and identifies if a gene is highly variable or not.
4. Dimensionality Reduction
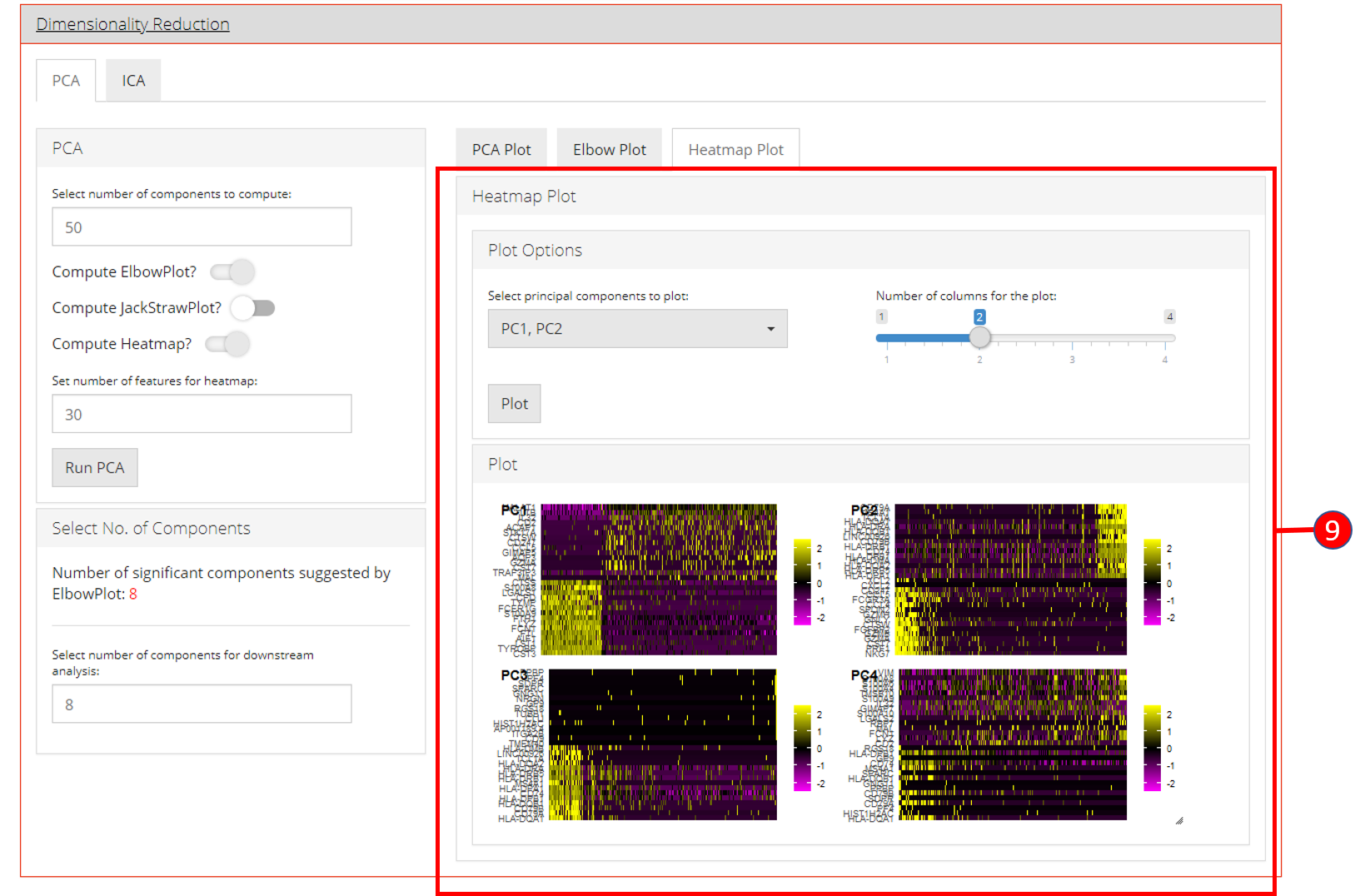
Seurat workflow offers PCA or ICA for dimensionality reduction and the components from these methods can be used in the downstream analysis. Moreover, several plots are available for the user to inspect the output of the dimensionality reduction such as the standard ‘PCA Plot’, ‘Elbow Plot’, ‘Jackstraw Plot’ and ‘Heatmap Plot’.
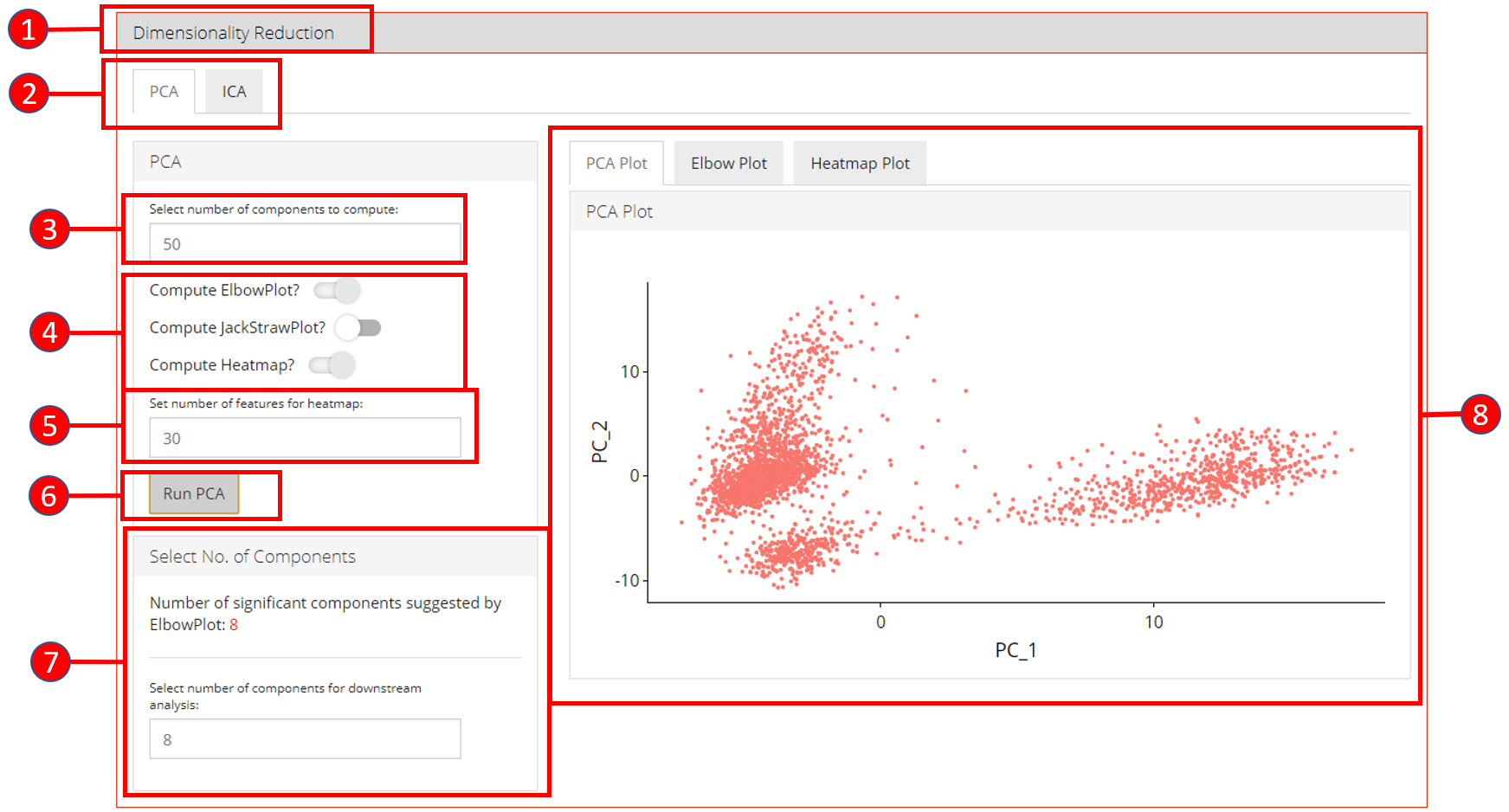
- Open up the ‘Dimensionality Reduction’ tab.
- Select a sub-tab for either ‘PCA’ or ‘ICA’ computation. Separate tabs are available for both methods if the user wishes to compute and inspect both separately.
- Input the number of components to compute. Default value is
50. - Select the plots that should be computed with the overall processing. The standard ‘PCA Plot’ will be computed at all times, while the remaining can be turned off if not required.
- Input the number of features against which a ‘Heatmap’ should be plotted. Only available when ‘Compute Heatmap’ is set to
TRUE. - Press the ‘Run PCA’ button to start processing.
- Select the number of computed components that should be used in the downstream analysis e.g. in ‘tSNE/UMAP’ computation or with ‘Clustering’. If ‘Elbow Plot’ is computed, a suggested value will be indicated that should be preferred for downstream analysis.
- The plot area from where all computed plots can be viewed by the user.
- Heatmap plot has various options available for the users to customize the plot. Since a plot is computed against each component, a user-defined number of components can be selected against. Moreover, for viewing quality, a number of columns can be selected in which the plots should be shown.
5. tSNE/UMAP
‘tSNE’ and ‘UMAP’ can be computed and plotted once components are available from ‘Dimensionality Reduction’ tab.
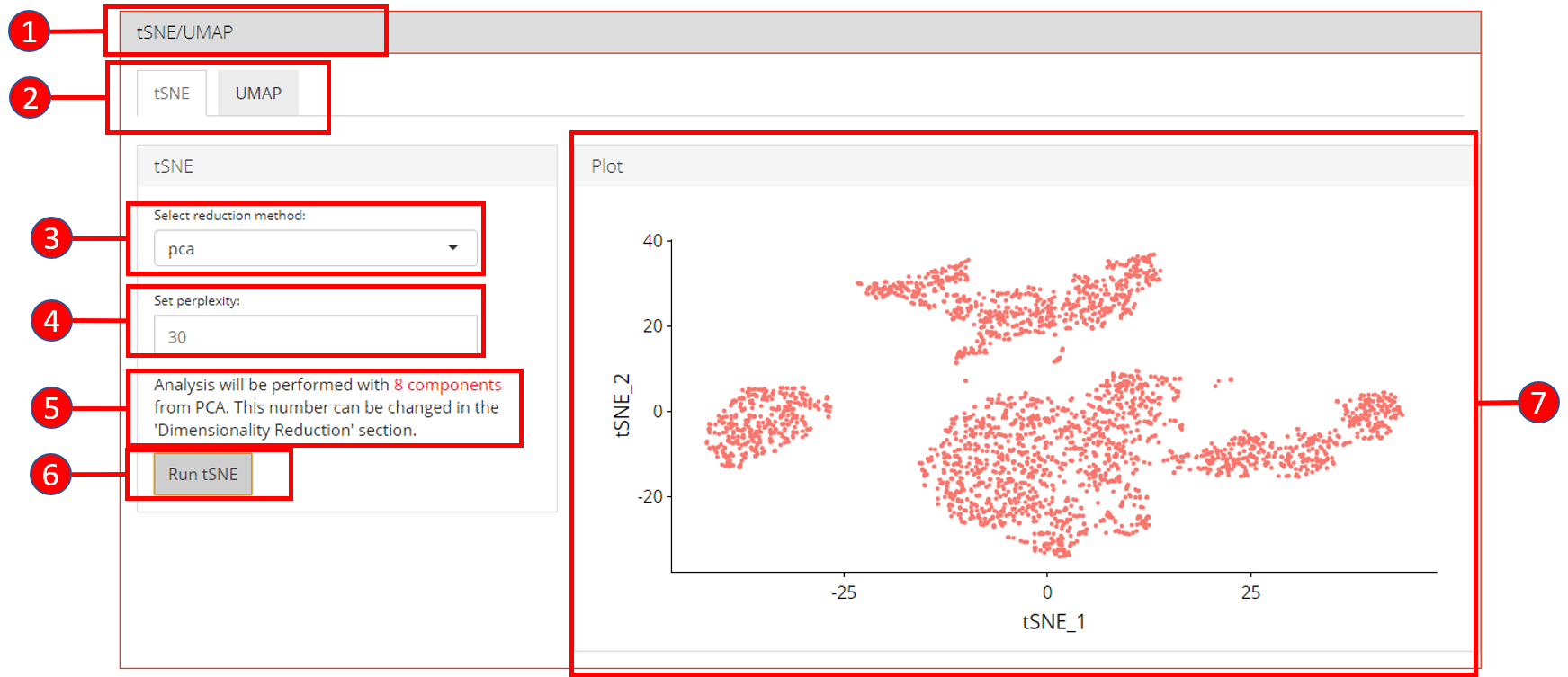
- Open up the ‘tSNE/UMAP’ tab.
- Select ‘tSNE’ or ‘UMAP’ sub-tab.
- Select a reduction method. Only methods that are computed previously in the ‘Dimensionality Reduction’ tab are available.
- Set perplexity tuning parameter.
- Information displayed to the user that how many components from the selected reduction method will be used. This value can only be changed from the ‘Dimensionality Reduction’ tab.
- Press ‘Run tSNE’ or ‘Run UMAP’ button to start processing.
- ‘tSNE’ or ‘UMAP’ plot depending upon the selected computation.
6. Clustering
Cluster labels can be generated for all cells/samples using one of the computed reduction method. Plots are automatically re-computed with cluster labels. The available algorithms for clustering as provided by Seurat include original Louvain algorithm, Louvain algorithm with multilevel refinement and SLM algorithm.
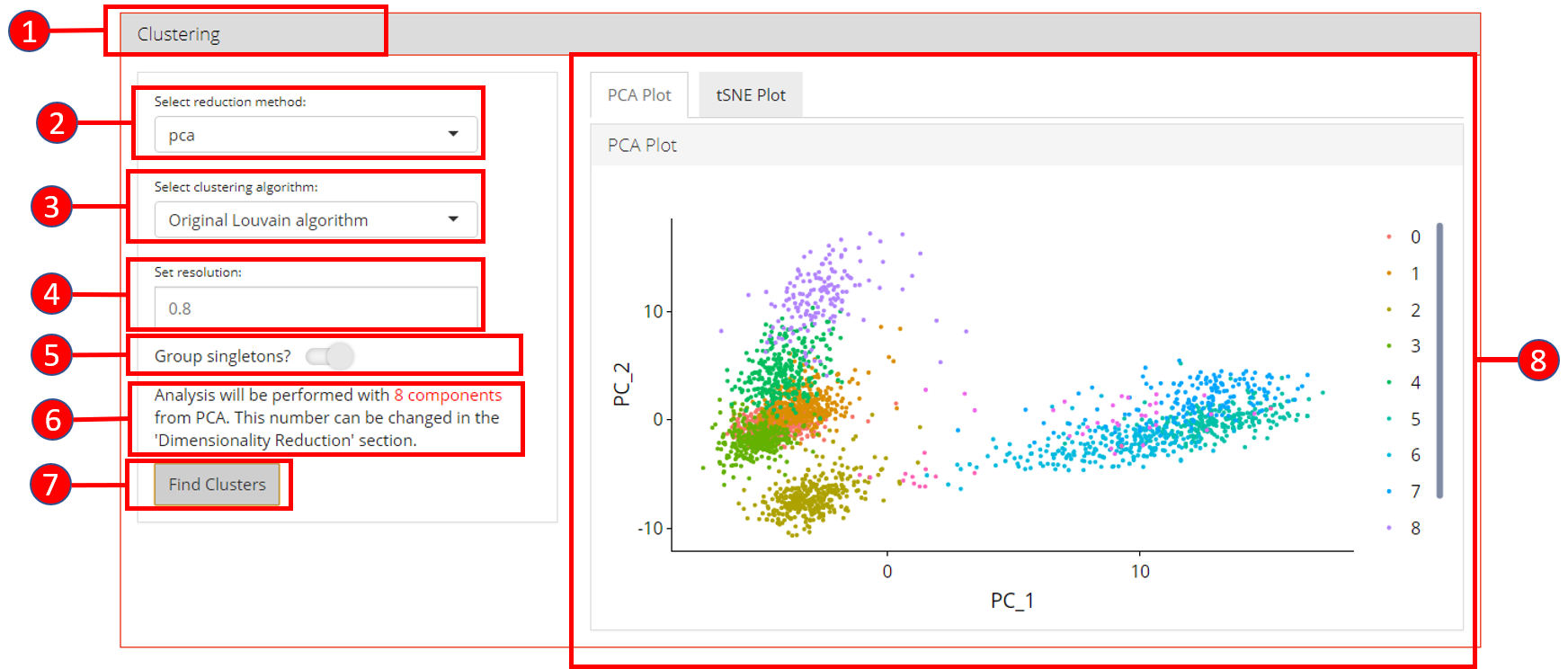
- Open up the ‘Clustering’ tab.
- Select a previously computed reduction method.
- Select clustering algorithm from
original Louvain algorithm,Louvain algorithm with multilevel refinementandSLM algorithm - Set resolution parameter value for the algorithm. Default is
0.8. - Set if singletons should be grouped to nearest clusters or not. Default is
TRUE. - Information displayed to the user that how many components from the selected reduction method will be used. This value can only be changed from the ‘Dimensionality Reduction’ tab.
- Press ‘Find Clusters’ button to start processing.
- Re-computed plots with cluster labels. Only those plots are available that have previously been computed.
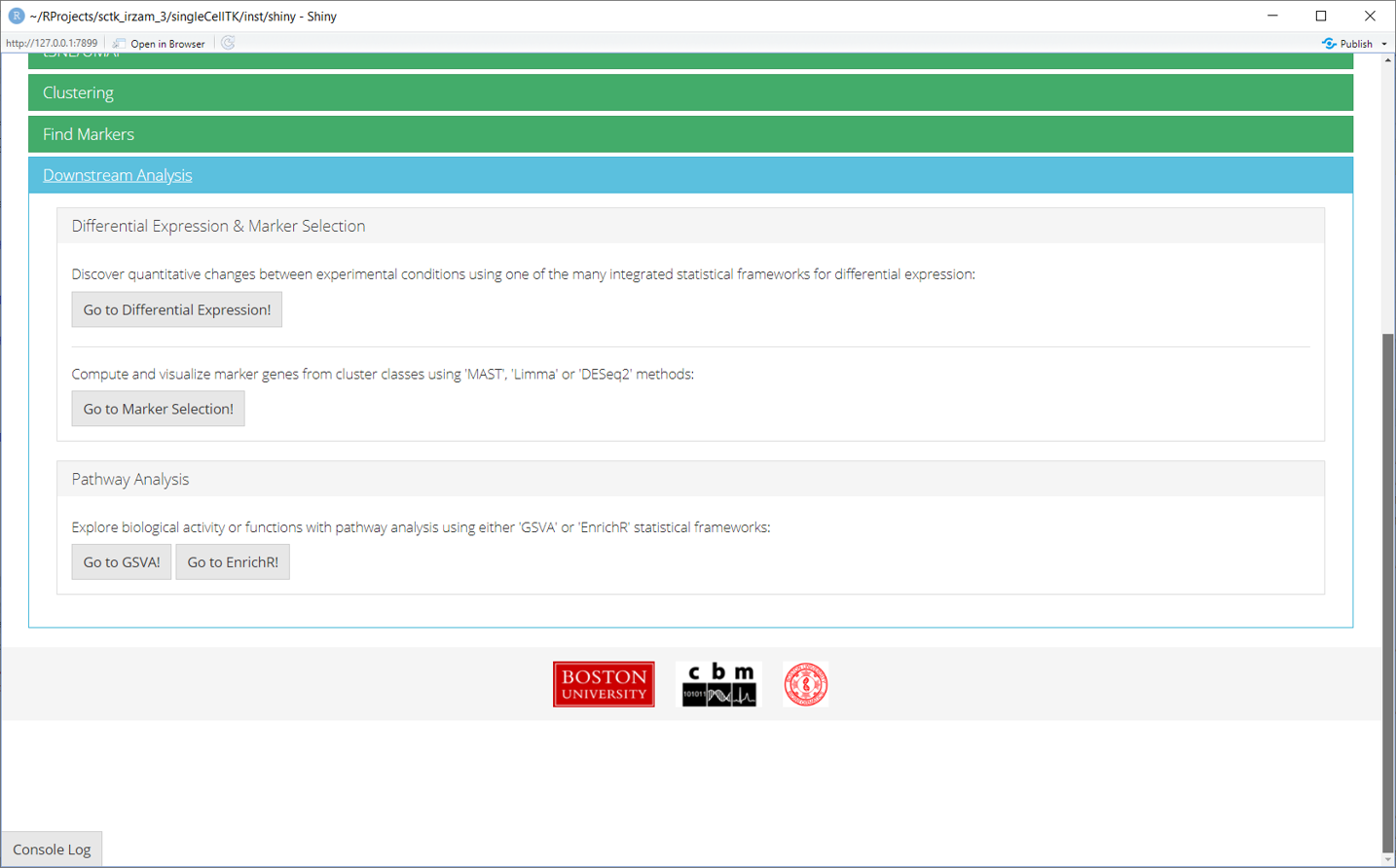
7. Find Markers
‘Find Markers’ tab can be used to identify and visualize the marker genes using on of the provided visualization methods. The tab offers identification of markers between two selected phenotype groups or between all groups and can be decided at the time of the computation. Furthermore, markers that are conserved between two phenotype groups can also be identified. Visualizations such as Ridge Plot, Violin Plot, Feature Plot and Heatmap Plot can be used to visualize the individual marker genes.
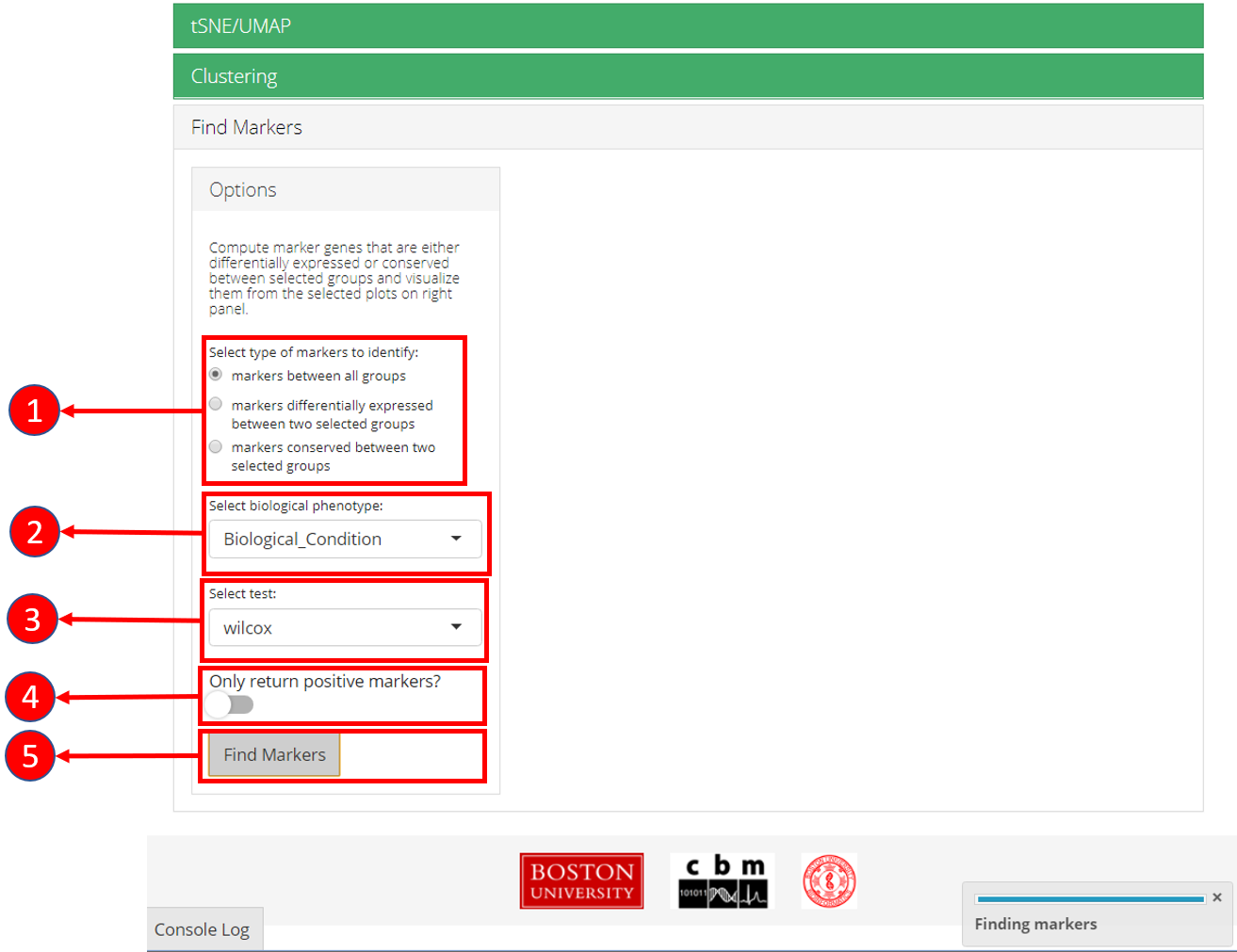 1. Select if you want to identify marker genes against all groups in a biological variable or between two pre-defined groups. Additionally, users can select the last option to identify the marker genes that are conserved between two groups. 2. Select phenotype variable that contains the grouping information. 3. Select test used for marker genes identification. 4. Select if only positive markers should be returned. 5. Press “Find Markers” button to run marker identification.
1. Select if you want to identify marker genes against all groups in a biological variable or between two pre-defined groups. Additionally, users can select the last option to identify the marker genes that are conserved between two groups. 2. Select phenotype variable that contains the grouping information. 3. Select test used for marker genes identification. 4. Select if only positive markers should be returned. 5. Press “Find Markers” button to run marker identification.
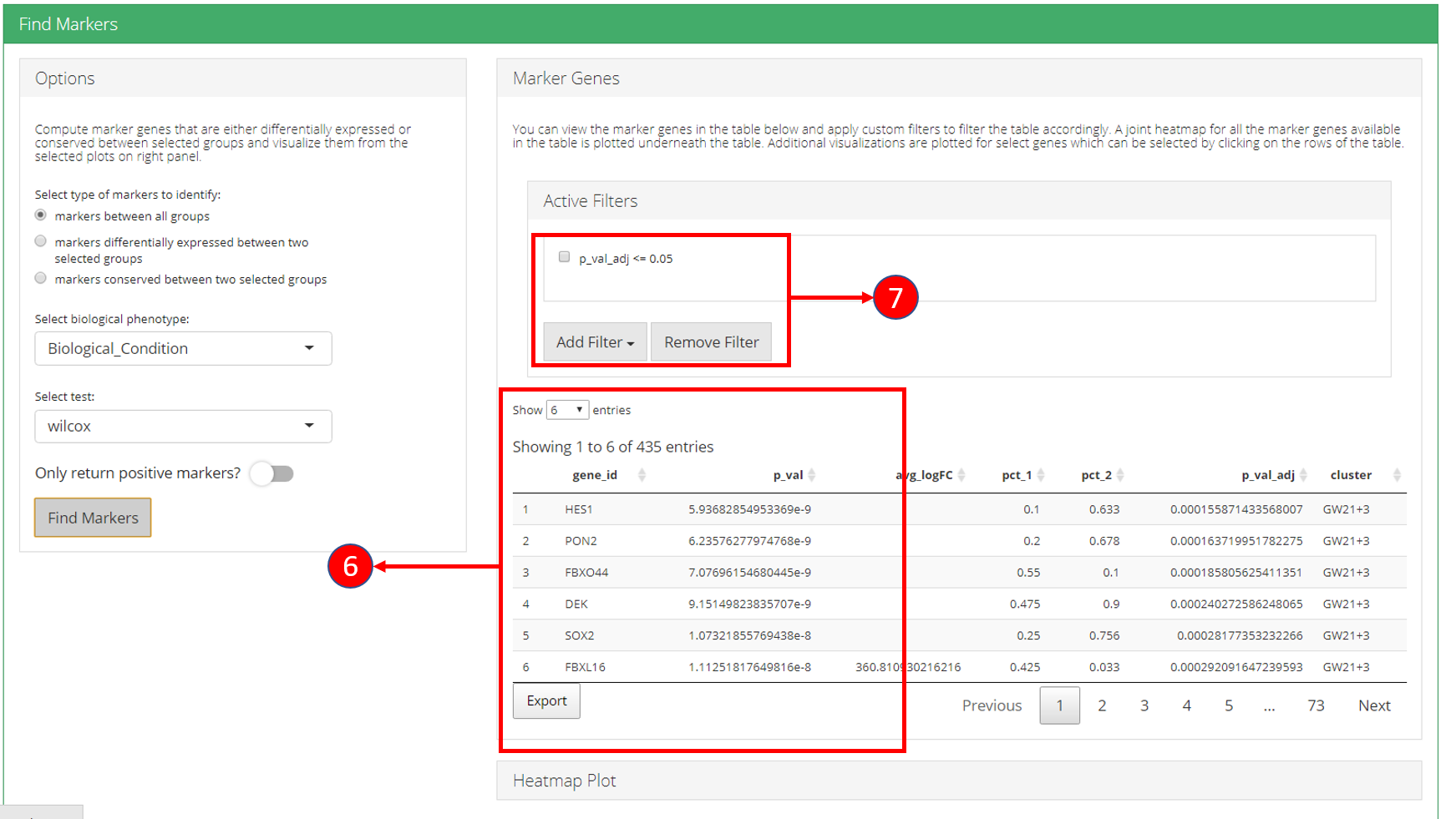 6. Identified marker genes are populated in the table. 7. Filters can be applied on the table.
6. Identified marker genes are populated in the table. 7. Filters can be applied on the table.
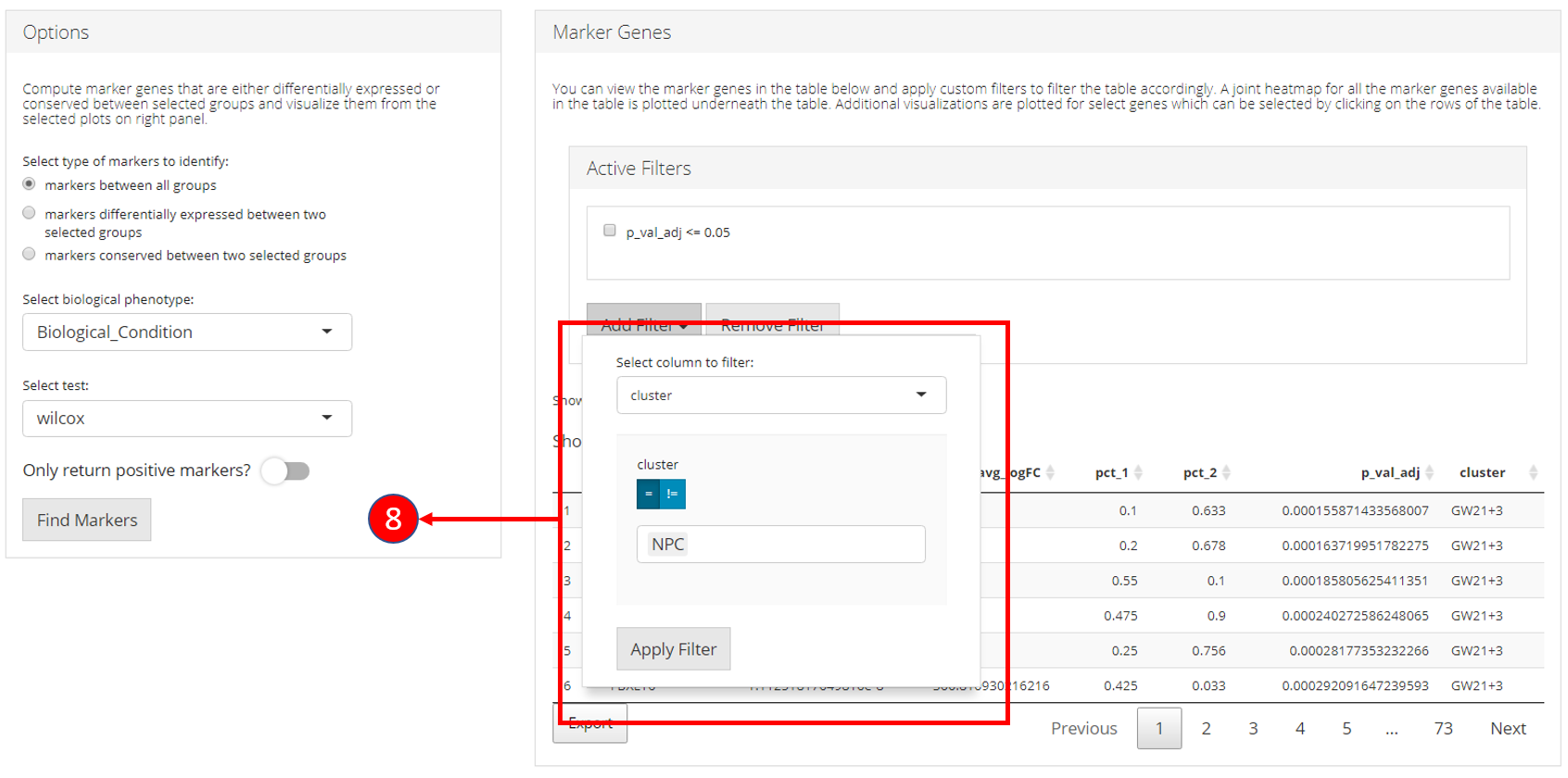 8. Filters allow different comparisons based on the type of the column of the table.
8. Filters allow different comparisons based on the type of the column of the table.
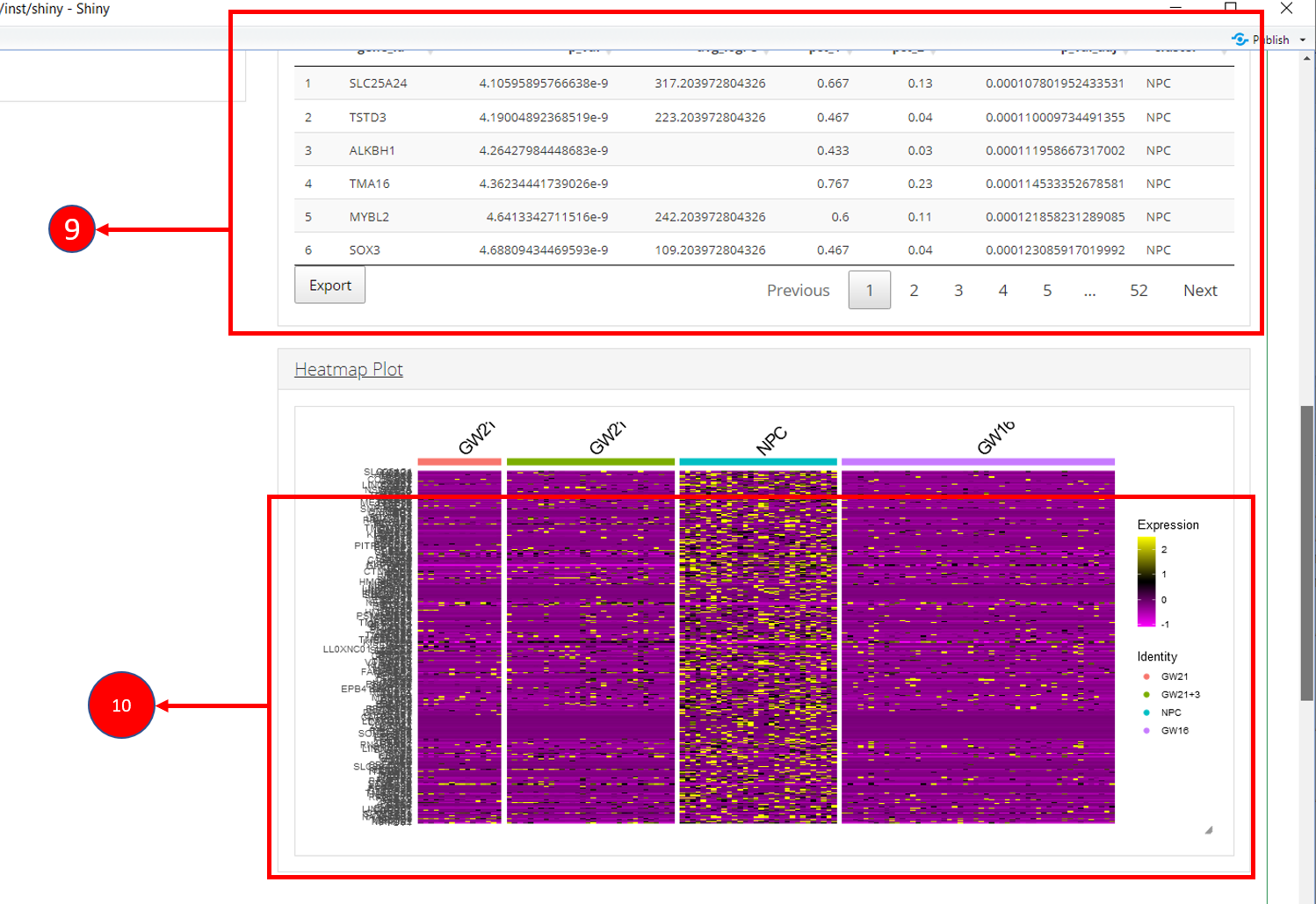 9. Table re-populated after applying filters. 10. Heatmap plot can be visualized for all genes populated in the table (9) against all biological groups in the selected phenotype variable.
9. Table re-populated after applying filters. 10. Heatmap plot can be visualized for all genes populated in the table (9) against all biological groups in the selected phenotype variable.
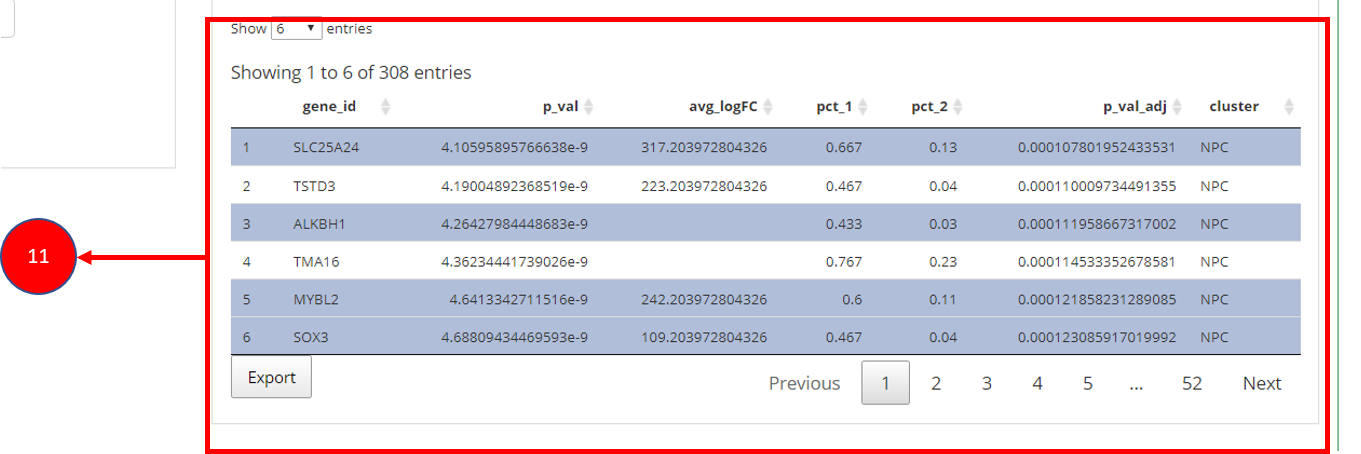 11. To visualize each individual marker gene through gene plots, they can be selected by clicking on the relevant rows of the table.
11. To visualize each individual marker gene through gene plots, they can be selected by clicking on the relevant rows of the table.
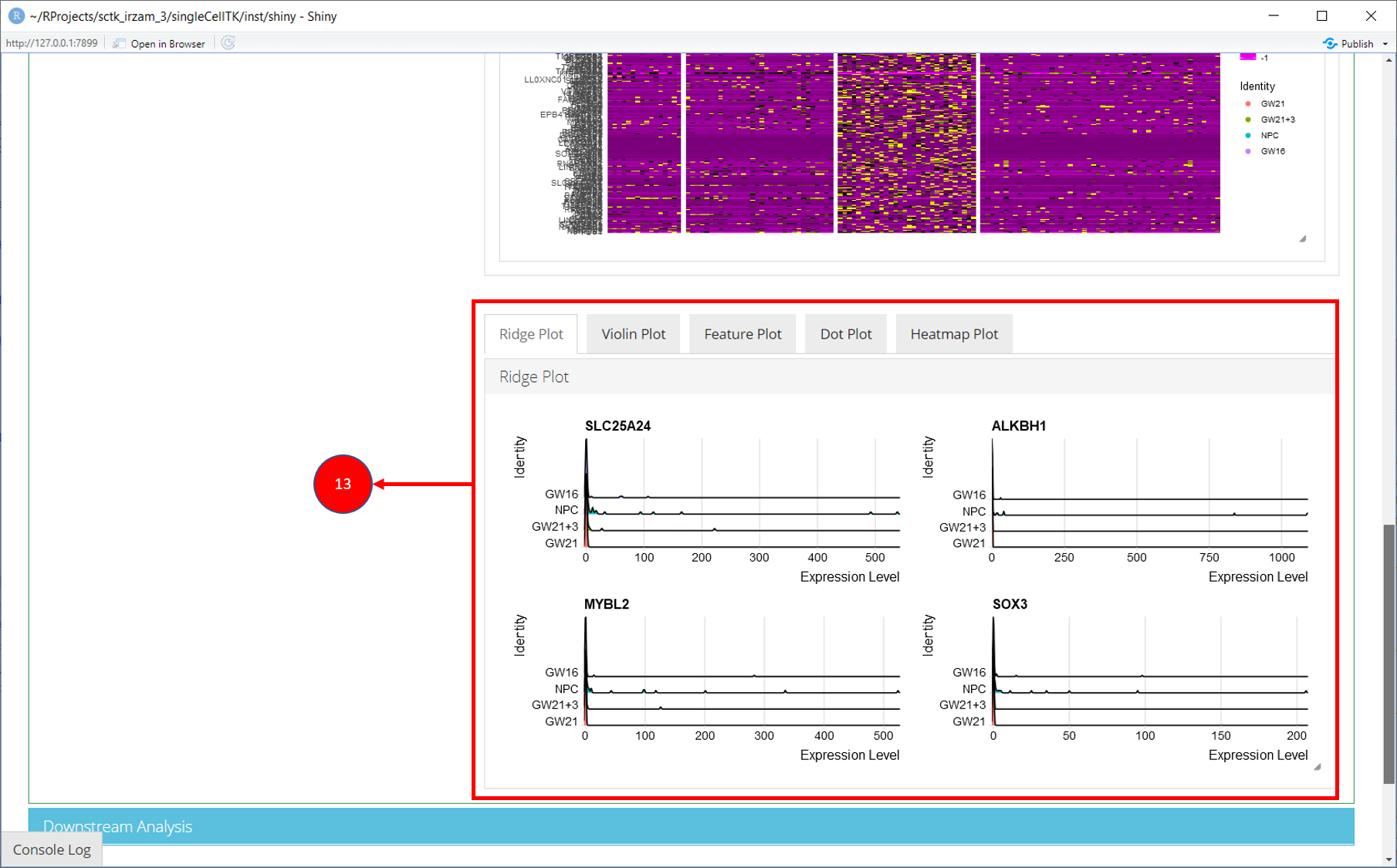 12. Selected marker genes from the table are plotted with gene plots.
12. Selected marker genes from the table are plotted with gene plots.